Parallelism
Created: March 15, 2025 1:58 PM Tags: Computer Hardware
Taxonomy of Execution
- SISD - single instruction, single data
- eg: add: sum 2 numbers and produce one result
- MIMD - multiple instruction, multiple data
- eg: multi-core
- SIMD - single instruction, multiple data
- eg: one instruction operates many values, like add 2 array elements element wise
- vector
threads
- a thread is a flow of control
- a program counter
- a stack
- a set of registers
- all threads in one program share the same memory space
- same data table
- and how they communicate with each other (Mutexes)
non-determism
- paralell program results are not determined
- outcome depends on how the memory acccess are interleaved
multi thread PE
- suppose all treads do equal work, there are T threads
- in the best case, each thread does 1/T of total work
- CT may drop due to thermal effect, IC, CPI my increase due to sync. overhead
$$
ET_\text{perThread} = ET / T \ \text{speed up} = T $$
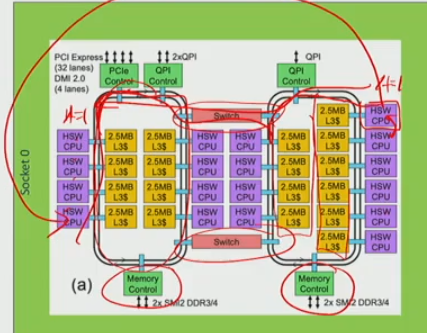
multi processor memory system
- a complete processor contains
- pipeline
- L1, L2 cache, they are private to each CPU
- L3 cache is shared among CPUs
- comm latency is not uniform, varies based on the distance to other CPUs or memory banks
Cache line invalidation
- caused by a store in one of the CPU’s L1,L2 cache, and needs to be synced across all cores
- caches are coherent, managed by coherence protocal
- all cores agree the same content of memory
- allows multiple headers, ensures there is only even one writer
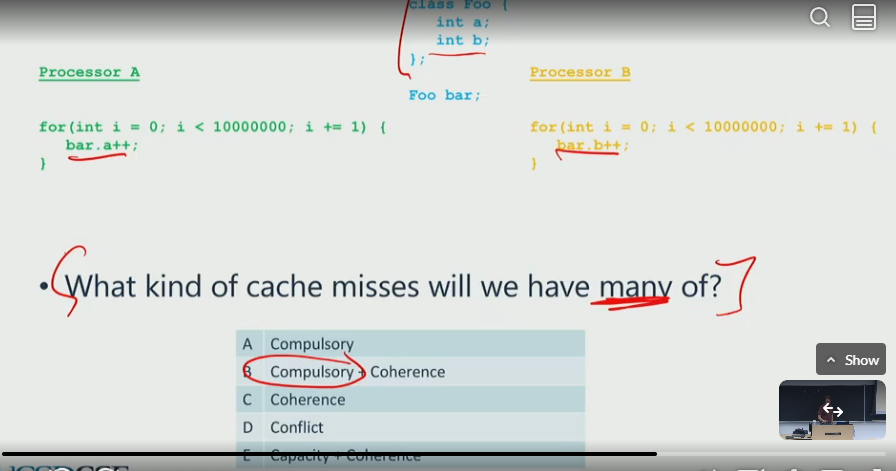
coherence misses
A miss that occurs in a multiprocessor system when a cache block is invalidated because another processor modified the shared data.
- a cache miss is a coherence miss - if the cache line was there but it is invalidated
- suppose in CPU 1, x=10 is updated to 20, the CPU 2 where x = 10 will be invalidated and force fetch from the updated value
load cache miss
- can come from
- The L1, L2cache on a different core.
- main memory
example:

- here is what gonna happen, in one random run:
| Event | Coherence action | CPU A cache | CPU B cache | memory |
|---|---|---|---|---|
| A: t = array[0] | A - compulsory cache miss | [10,11,12,13] | … | [10,11,12,13] |
| A: array[0] = 11 | A- cache hit | [11,11,12,13] | … | [10,11,12,13] |
| B: t = array[0] | B - compulsory cache miss, copy from A | [11,11,12,13] | [11,11,12,13] | [10,11,12,13] |
| B: array[0] = 12 | B - cache hit, invalidate A | invalidate | [12,11,12,13] | [10,11,12,13] |
| A: t = array[1] | A - coherence cache miss, copy from B | [12,11,12,13] | [12,11,12,13] | [10,11,12,13] |
| A: array[1] = 12 | A- cache hit, invalidate B | [12,12,12,13] | invalidate | [10,11,12,13] |
| B: t = array[1] | B - coherance cache miss, copy from A | [12,12,12,13] | [12,12,12,13] | [10,11,12,13] |
| B: array[1] = 13 | B - cache hit, invalidate A | invalidate | [12,13,12,13] | [10,11,12,13] |
locks
lock make sure other threads cannot access the resources this thread already used. MAKE SURE TO
UNLOCK after
- we can define lock:
std:mutex lock

- is the program deterministc?
- NO, if B executes before A, result is different
cost of sharing memory
- copying and invaliding cache lines are expensive and takes a lot of time
- writing is a big deal, however, sharing READ ONLY is not a problem
- sharing leads to coherence misses
- we can do
- per-thread data structure
- minimize lock acquire/release
example:

- there will be compulsory misses, 1 per cache line get
- there will be a lot coherence misses, since lock is also shared across processors.
- lock/unlock lock will invalidate others.
resolve thread data conherence misses
- give each thread own data
- merge at the end
false sharing
example:

- the program is determinstic
- although there is no sharing between the threads, there are still coherence misses, because we shared the cache lines but not the data
- law of sharing: all small, shared, more than very occcasionally updatd objects should be cache line aligned.
example:
- there is only 1 compulsory misses when each processor loads, therefore we can ignore it
- since bar fields are cached on the same cache line, a lot of coherence miss will occur
Use Threads
OpenMP (open multiprocessing)
- high level API for parallelism C and C++ code
- relatively easy
- most applicable to paralleizing simple loops
❌ (a) OpenMP requires manual thread creation and synchronization.
- Incorrect because OpenMP automatically handles thread creation and workload distribution using simple directives (e.g.,
#pragma omp parallel). - Unlike pthreads, where manual thread management is required.
#pragma omp critical- To enforce mutual exclusion, allowing only one thread to execute the enclosed code at a time
pthreads/C++ threads
- low level API
- relatively hard
example:

- the working set size is 256 *8 = 2kb, this is a relatively small working set and can be cached without capacity miss on modern design. therefore, tilling does not help much
- function inlining does not help because
__attribute__((noinline))is defined, which explicitly tell the complier not to inlineing the function - loop unrolling would help, it reduce overhead
- there is no redudent execution so common sub-expression elimination dont help
-
splot loop does not help since it does not address memroy access patterns or memory redundency
-
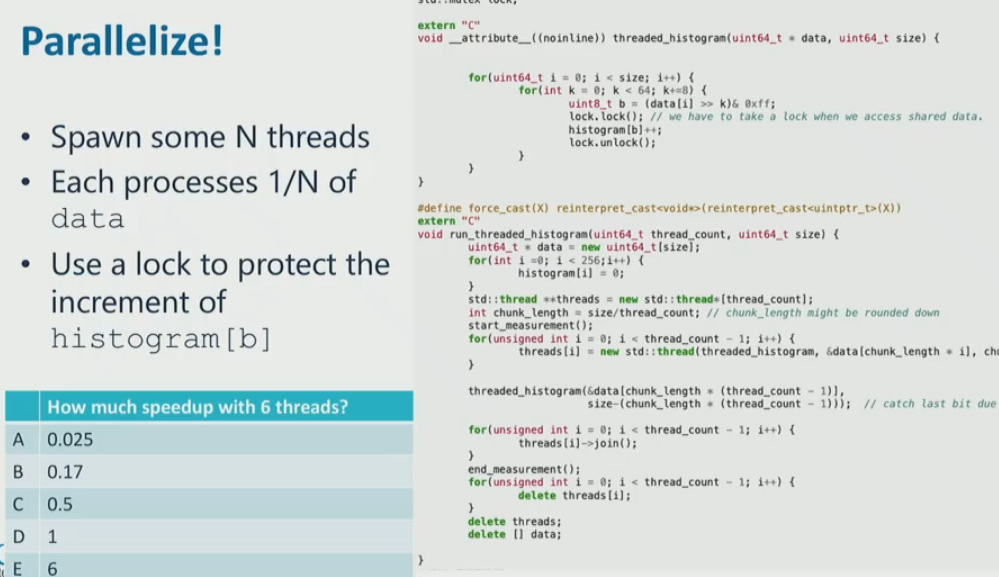
now, suppose we have N threads, and each process 1/N of data
-
suppose we use lock to protect increment of histogram[b]
-
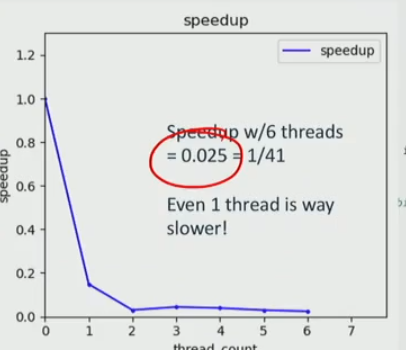
what is speed up of 6 threads
- it would be even worse, because the lock transfer produce a lot of coherence misses, which essentially cause all the threads to wait for the other to update + additional coherence misses and validations
-
to improve
- currently, we have shared buckets, and shared lock for all threads
- we can improve a little by make a private lock for each bucket (therefore threads dont contests locks a lot (since lock occupy entire cacheline, so no coherence misses here)
- but the threads still needs to wait to write into the historgram bucket
b, this will still cause massive coherence misses
- but the threads still needs to wait to write into the historgram bucket
-
use thread-private buckets: create 256 * 6 buckets, so each thread will have their own buckets for the histogram, and in the end we need to combine them. ****in this case, define cache line like
buckets[bucket_num*thread_count + thread_id] = valfor each loop- it has a good speedup, but the coherence miss still present.
-
since the buckets are created like following continous pattern, and each bucket is an int, multiple buckets would be on the same cacheline, and when one of them gets updated, a false sharing would still occur to invalidate all other buckets in the same cache, even they are unrelated. this still cause coherence misses

-
to fix it, we can use thread-private buckets and let each bucket occupy entire cache line. in this case, define buckets as
buckets[thread_id * 256 + bucket_number ] = valfor each loop. therefore, instead of same bucket number from different threads are adjacent to each other, we make same threads buckets adjacent to each other. therefore, we avoid most coherence misses, there are still some coherence misses possible in the cache line that contains buckets from differnt threads.-
and we also eliminated all locks!

-
-
original
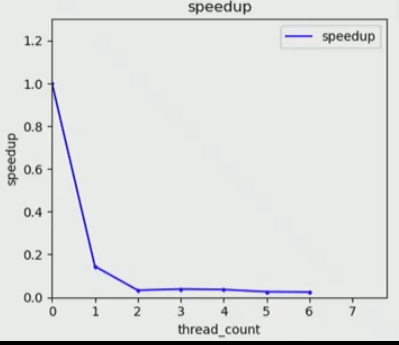
private lock for each shared bucket
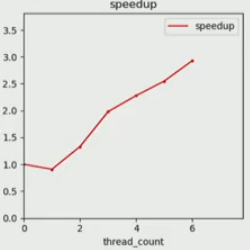
private bucket for each thread, grouped by bucket numbers
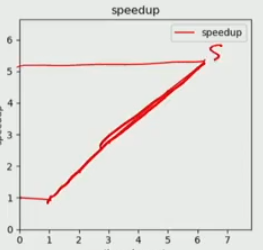
private buckets for each thread, grouped by threads
summary parallelism speedup
- we need to do some aggressive optimization that complier cannot do for us
- eliminate (or reduce) lock contention
- eliminate false sharing
- eliminate true sharing
- redesign our data structure to do above
- private caches
- most modern processors
- L1, L2 are private caches to each core
- provides faster access to frequently used data for single core
- when the cached values gets update in the other core, coherence manager invalidates cache in this core so the next time this core needs to access the value, it will copy from the updated cache to ensure memory consistency
- in addition, registers files are private to each core
- registers can not be shared
- L1, L2 are private caches to each core
- most modern processors
- shared caches
- LLC (l3) is typicall shared amongst cores to help access data without going to memory
- shared cache access time is different for different cores
- coherence
- L1, L2 cache value is same across
- L3, DRAM, and other further storage (DIMM) value is same
- cached value can be different in the above 2 groups
- threads
- a thread has their own register file (incl. PC), L1, L2 cache
- to make use of multi processors
- share the same address space with other threads in the same program
Vector, and SIMD
- where a single isntruction operates on multiple data values of same type
- for example, adding 2 vector element wise

- CPI = 1, cycles/addition = 0,25
- floating point, huge arrays
- machine learning
- scientifc computing
- floating point, short arrays
- 3D graphics
- media (mixed float/int)
- floating point, huge arrays
🔹 Arithmetic Instructions
| Instruction | Description | Width |
|---|---|---|
ADDPS |
Add packed single-precision floats | 128-bit |
ADDPD |
Add packed double-precision floats | 128-bit |
VADDPS |
Add packed single-precision floats | 256/512-bit |
MULPS |
Multiply packed single-precision floats | 128-bit |
VMULPS |
Multiply packed single-precision floats | 256/512-bit |
SUBPS |
Subtract packed floats | 128-bit |
VSUBPS |
Subtract packed floats (AVX) | 256/512-bit |
DIVPS |
Divide packed single-precision floats | 128-bit |
🔹 Logical Instructions
| Instruction | Description | Width |
|---|---|---|
ANDPS |
Bitwise AND of packed floats | 128-bit |
VANDPS |
Bitwise AND of packed floats (AVX) | 256/512-bit |
ORPS |
Bitwise OR | 128-bit |
XORPS |
Bitwise XOR | 128-bit |
VORPS |
Bitwise OR (AVX) | 256/512-bit |
VXORPS |
Bitwise XOR (AVX) | 256/512-bit |
🔹 Data Movement
| Instruction | Description | Width |
|---|---|---|
MOVAPS |
Move aligned packed floats | 128-bit |
MOVUPS |
Move unaligned packed floats | 128-bit |
VMOVAPS |
Move aligned packed floats (AVX) | 256/512-bit |
VMOVUPS |
Move unaligned packed floats (AVX) | 256/512-bit |
🔹 Permute / Shuffle
| Instruction | Description | Width |
|---|---|---|
SHUFPS |
Shuffle packed floats | 128-bit |
VSHUFPS |
Shuffle packed floats (AVX) | 256/512-bit |
PERMPS |
Permute single-precision floats (AVX2) | 256-bit |
VPERMQ |
Permute 64-bit elements (AVX2/AVX-512) | 256/512-bit |
🔹 Comparison / Masking
| Instruction | Description | Width |
|---|---|---|
CMPPS |
Compare packed floats | 128-bit |
VCMPPS |
Compare packed floats (AVX) | 256/512-bit |
BLENDPS |
Blend packed floats based on mask | 128-bit |
VBLENDVPS |
Variable blend using mask (AVX) | 256-bit |